You're reading the documentation of the v0.9. For the latest released version, please have a look at v1.2.
Differential equation resolution
Introduction
We present here a Perceval implementation of a Quantum Machine Learning algorithm for solving differential equations. Its aims is to approximate the solution to the differential equation considered in [1]:
with boundary condition \(f(0)=f_{0}\). The analytical solution is \(f(x)=f_0\exp (-\kappa \lambda x) \cos (\lambda x)\).
QML Loss Function Definition
In order to use QML to solve this differential equation, we first need to derive from it a loss function whose minimum is associated to its analytical solution.
Let \(F\left[\left\{d^{m} f / d x^{m}\right\}_{m},f, x\right]=0\) be a general differential equation verified by \(f(x)\), where \(F[.]\) is an operator acting on \(f(x)\), its derivatives and \(x\). For the solving of a differential equation, the loss function described in [1] consists of two terms
The first term \(\mathcal{L}_{\boldsymbol{\theta}}^{(\mathrm{diff})}\) corresponds to the differential equation which has been discretised over a fixed regular grid of \(M\) points noted \(x_i\):
where \(L(a,b) := (a - b)^2\) is the squared distance between two arguments. The second term \(\mathcal{L}_{\boldsymbol{\theta}}^{(\text {boundary })}\) is associated to the initial conditions of our desired solution. It is defined as:
where \(\eta\) is the weight granted to the boundary condition and \(f_{0}\) is given by \(f(x_0) = f_0\).
Given a function approximator \(f^{(n)}(x, \boldsymbol{\theta}, \boldsymbol{\lambda})\), the loss function above will be minimised using a classical algorithm, updating the parameters \(\boldsymbol{\theta}\) based on samples obtained using a quantum device.
Quantum circuit architecture
The feature map used is presented in [2,3,4]. The quantum circuit architecture from [4] is expressed as \(\mathcal{U}(x, \boldsymbol{\theta}):=\mathcal{W}^{(2)}\left(\boldsymbol{\theta}_{2}\right) \mathcal{S}(x) \mathcal{W}^{(1)}\left(\boldsymbol{\theta}_{1}\right).\) The phase-shift operator \(\mathcal{S}(x)\) incorporates the \(x\) dependency of the function we wish to approximate. It is sandwiched between two universal interferometers \(\mathcal{W}^{(1)}(\boldsymbol{\theta_1})\) and \(\mathcal{W}^{(2)}(\boldsymbol{\theta_2})\), where the beam-splitter parameters \(\boldsymbol{\theta_1}\) and \(\boldsymbol{\theta_2}\) of this mesh architecture are tunable to enable training of the circuit. The output measurement operator, noted \(\mathcal{M}(\boldsymbol{\lambda})\), is the projection on the Fock states obtained using photon-number resolving detectors, multiplied by some coefficients \(\boldsymbol{\lambda}\) which can also be tunable. Formally, we have:
where the sum is taken over all \(\binom{n+m-1}{n}\) possible Fock states considering \(n\) photons in \(m\) modes. Let \(\mathbf{\left | n^{(i)}\right \rangle} = \left |n^{(i)}_1,n^{(i)}_2,\dots,n^{(i)}_m\right \rangle\) be the input state consisting of \(n\) photons where \(n^{(i)}_j\) is the number of photons in input mode \(j\). Given these elements, the circuit’s output \(f^{(n)}(x, \boldsymbol{\theta}, \boldsymbol{\lambda})\) is given by the following expectation value:
This expression can be rewritten as the following Fourier series [4]
where \(\Omega_n = \{-n, -n+1, \dots, n-1, n \}\) is the frequency spectrum one can reach with \(n\) incoming photons and \(\{c_\omega(\boldsymbol{\theta}, \boldsymbol{\lambda})\}\) are the Fourier coefficients. The \(\boldsymbol{\lambda}\) parameters are sampled randomly in the interval \([-a;a]\), with \(a\) a randomly chosen integer. \(f^{(n)}(x, \boldsymbol{\theta}, \boldsymbol{\lambda})\) will serve as a function approximator for this chosen differential equation. Differentiation in the loss function is discretised as \(\frac{df}{dx} \simeq \frac{f(x+\Delta x) - f(x-\Delta x)}{2\Delta x}\).
\(n, m,\) and \(\boldsymbol{\lambda}\) are variable parameters defined below. \(\Delta x\) is the mesh size.
Perceval Simulation
Initialisation
[1]:
import perceval as pcvl
import numpy as np
from math import comb
from scipy.optimize import minimize
import time
import matplotlib.pyplot as plt
import matplotlib as mpl
import tqdm as tqdm
We will run this notebook with 4 photons. We could use more photons, but the result with 4 photons is already satisfying.
[2]:
nphotons = 4
Differential equation parameters
We define here the value of the differential equation parameters and boundary condition \(\lambda, \kappa, f_0\).
[3]:
# Differential equation parameters
lambd = 8
kappa = 0.1
def F(u_prime, u, x): # DE, works with numpy arrays
return u_prime + lambd * u * (kappa + np.tan(lambd * x))
[4]:
# Boundary condition (f(x_0)=f_0)
x_0 = 0
f_0 = 1
[5]:
# Modeling parameters
n_grid = 50 # number of grid points of the discretized differential equation
range_min = 0 # minimum of the interval on which we wish to approximate our function
range_max = 1 # maximum of the interval on which we wish to approximate our function
X = np.linspace(range_min, range_max-range_min, n_grid) # Optimisation grid
[6]:
# Differential equation's exact solution - for comparison
def u(x):
return np.exp(- kappa*lambd*x)*np.cos(lambd*x)
[7]:
# Parameters of the quantum machine learning procedure
N = nphotons # Number of photons
m = nphotons # Number of modes
eta = 5 # weight granted to the initial condition
a = 200 # Approximate boundaries of the interval that the image of the trial function can cover
fock_dim = comb(N + m - 1, N)
# lambda coefficients for all the possible outputs
lambda_random = 2 * a * np.random.rand(fock_dim) - a
# dx serves for the numerical differentiation of f
dx = (range_max-range_min) / (n_grid - 1)
[8]:
# Input state with N photons and m modes
input_state = pcvl.BasicState([1]*N+[0]*(m-N))
print(input_state)
|1,1,1,1>
Definition of the circuit
We will generate a Haar-random initial unitary using QR decomposition built in Perceval Matrix.random_unitary, the circuit is defined by the combination of 3 sub-circuits - the intermediate phase is a parameter.
[9]:
"Haar unitary parameters"
# number of parameters used for the two universal interferometers (2*m**2 per interferometer)
parameters = np.random.normal(size=4*m**2)
px = pcvl.P("px")
c = pcvl.Unitary(pcvl.Matrix.random_unitary(m, parameters[:2 * m ** 2]), name="W1")\
// (0, pcvl.PS(px))\
// pcvl.Unitary(pcvl.Matrix.random_unitary(m, parameters[2 * m ** 2:]), name="W2")
backend = pcvl.BackendFactory().get_backend("SLOS")
backend.set_circuit(pcvl.Unitary(pcvl.Matrix.random_unitary(m)))
backend.preprocess([input_state])
pcvl.pdisplay(c)
[9]:

Expectation value and loss function computation
The expectation value of the measurement operator \(\mathcal{M}(\boldsymbol{\lambda})\) is obtained directly from Fock state probabilities computed by Perceval. Given this expectation value, the code snippet below computes the loss function defined in the Introduction.
Note the use of the all_prob simulator method giving directly access to the probabilities of all possible output states, including null probabilities. This calculation is optimized in SLOS backend.
[10]:
def computation(params):
global current_loss
global computation_count
"compute the loss function of a given differential equation in order for it to be optimized"
computation_count += 1
f_theta_0 = 0 # boundary condition
coefs = lambda_random # coefficients of the M observable
# initial condition with the two universal interferometers and the phase shift in the middle
U_1 = pcvl.Matrix.random_unitary(m, params[:2 * m ** 2])
U_2 = pcvl.Matrix.random_unitary(m, params[2 * m ** 2:])
px = pcvl.P("x")
c = pcvl.Unitary(U_2) // (0, pcvl.PS(px)) // pcvl.Unitary(U_1)
px.set_value(np.pi * x_0)
backend.set_circuit(c)
f_theta_0 = np.sum(np.multiply(backend.all_prob(input_state), coefs))
# boundary condition given a weight eta
loss = eta * (f_theta_0 - f_0) ** 2 * len(X)
# Y[0] is before the domain we are interested in (used for differentiation), x_0 is at Y[1]
Y = np.zeros(n_grid + 2)
# x_0 is at the beginning of the domain, already calculated
Y[1] = f_theta_0
px.set_value(np.pi * (range_min - dx))
backend.set_circuit(c)
Y[0] = np.sum(np.multiply(backend.all_prob(input_state), coefs))
for i in range(1, n_grid):
x = X[i]
px.set_value(np.pi * x)
backend.set_circuit(c)
Y[i + 1] = np.sum(np.multiply(backend.all_prob(input_state), coefs))
px.set_value(np.pi * (range_max + dx))
backend.set_circuit(c)
Y[n_grid + 1] = np.sum(np.multiply(backend.all_prob(input_state), coefs))
# Differentiation
Y_prime = (Y[2:] - Y[:-2])/(2*dx)
loss += np.sum((F(Y_prime, Y[1:-1], X))**2)
current_loss = loss / len(X)
return current_loss
Classical optimisation
Finally the code below performs the optimisation procedure using the loss function defined in the previous section. To this end, we use a Broyden–Fletcher–Goldfarb–Shanno (BFGS) optimiser [5] from the SciPy library.
[11]:
def callbackF(parameters):
"""callback function called by scipy.optimize.minimize allowing to monitor progress"""
global current_loss
global computation_count
global loss_evolution
global start_time
now = time.time()
pbar.set_description("M= %d Loss: %0.5f #computations: %d elapsed: %0.5f" %
(m, current_loss, computation_count, now-start_time))
pbar.update(1)
loss_evolution.append((current_loss, now-start_time))
computation_count = 0
start_time = now
[12]:
computation_count = 0
current_loss = 0
start_time = time.time()
loss_evolution = []
pbar = tqdm.tqdm()
res = minimize(computation, parameters, callback=callbackF, method='BFGS', options={'gtol': 1E-2})
M= 4 Loss: 0.00866 #computations: 130 elapsed: 2.49080: : 105it [03:06, 1.63s/it]
After the optimisation procedure has been completed, the optimal unitary parameters (in res.x) can be used to determine the quantum circuit beam-splitter and phase-shifter angles for an experimental realisation.
[13]:
print("Unitary parameters", res.x)
Unitary parameters [-0.66334127 -0.04353921 -1.92172598 1.46311582 0.13834699 0.04840466
-1.92475716 0.94111392 0.04711636 1.6339162 1.56303605 -0.36947264
-0.88242141 0.63431897 -0.71258671 1.11715881 0.21961878 -0.32474614
0.96963211 0.25191156 -0.27099778 -1.41618548 2.5426048 -0.14291888
0.3290805 0.67119072 -1.54546836 1.43350362 0.44816853 -1.37555405
-0.46218774 1.05279649 0.90589211 -1.15132551 -0.48436678 0.10585881
-0.02193175 -0.80538581 -0.36660846 1.72574933 -0.05184236 -1.1402877
0.86127372 0.25229208 -0.15104874 -0.36761966 -0.56477874 1.2582815
-0.17414877 -1.20035746 0.67259315 -1.11251674 0.0161855 1.17097977
-1.0474133 1.0467571 -0.10005266 -0.71137126 1.03264364 -1.02637915
-0.04809381 -1.00089775 -0.78788374 -0.49447837]
Plotting the approximation
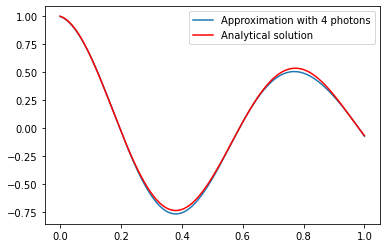
We now plot the result of our optimisation in order to compare the QML algorithm’s output and the analytical solution.
[14]:
def plot_solution(m, N, X, optim_params, lambda_random):
Y = []
U_1 = pcvl.Matrix.random_unitary(m, optim_params[:2 * m ** 2])
U_2 = pcvl.Matrix.random_unitary(m, optim_params[2 * m ** 2:])
px = pcvl.P("x")
c = pcvl.Unitary(U_2) // (0, pcvl.PS(px)) // pcvl.Unitary(U_1)
for x in X:
px.set_value(np.pi * x)
backend.set_circuit(c)
f_theta = np.sum(np.multiply(backend.all_prob(input_state), lambda_random))
Y.append(f_theta)
exact = u(X)
plt.plot(X, Y, label="Approximation with {} photons".format(N))
[15]:
X = np.linspace(range_min, range_max, 200)
# Change the plot size
default_figsize = mpl.rcParamsDefault['figure.figsize']
mpl.rcParams['figure.figsize'] = [2 * value for value in default_figsize]
plot_solution(m, N, X, res.x, lambda_random)
plt.plot(X, u(X), 'r', label='Analytical solution')
plt.legend()
plt.show()
[16]:
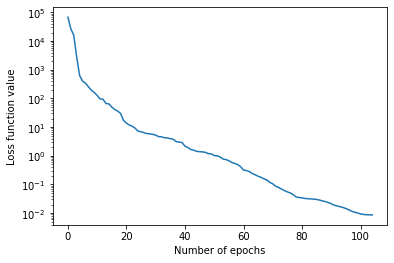
plt.plot([v[0] for v in loss_evolution])
plt.yscale("log")
plt.xlabel("Number of epochs")
plt.ylabel("Loss function value")
[16]:
Text(0, 0.5, 'Loss function value')
References
[1] O. Kyriienko, A. E. Paine, and V. E. Elfving, “Solving nonlinear differential equations with differentiable quantum circuits”, Physical Review A 103, 052416 (2021).
[2] A. Pérez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, “Data re-uploading for a universal quantum classifier”, Quantum 4, 226 (2020).
[3] M. Schuld, R. Sweke, and J. J. Meyer, “Effect of data encoding on the expressive power of variational quantum-machine-learning models”, Physical Review A 103, 032430 (2021).
[4] B. Y. Gan, D. Leykam, D. G. Angelakis, and D. G. Angelakis, “Fock State-enhanced Expressivity of Quantum Machine Learning Models”, in Conference on Lasers andElectro-Optics (2021), paper JW1A.73. Optica Publishing Group, (2021).
[5] R. Fletcher, Practical methods of optimization. John Wiley & Sons. (2013).